




Ulm News, 14.11.2018 18:00
Automatische Aufmerksamkeitserkennung: Wie erkennt der Computer, wenn der Mensch innerlich abschaltet? -




 schließen
schließen
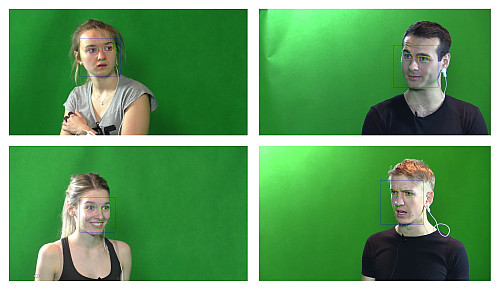
Beschreibung: Zur Emotionserkennung werden sogenannte Feature-Detektoren eingesetzt, die Gesichtszüge, Augen- und Mundbewegungen erfassen können;
Lizenz: © copyright
Fotograf: Neurodata Lab
Lizenz: © copyright
Der Mensch hat ein untrügliches Gespür dafür, ob sein Gegenüber ihm aufmerksam zuhört oder nicht. Denn die menschliche Mimik, Gestik und Körpersprache ist ziemlich aufschlussreich, zumindest für den Menschen. Forscher aus Ulm und Moskau haben untersucht, mit welchen Merkmalen ein Computer die Aufmerksamkeit von Menschen in Gesprächssituationen am besten erfassen kann.
Trainiert wurde das System mit mehr als 26 000 Videofragmenten. Das Ergebnis: der Zuhörer verrät mit seinem Sprechen am meisten über sein „Engagement“, so der Fachbegriff dafür. Die automatische Gefühlserkennung, im Englischen spricht man hier von Affective Computing, ist ein gleichermaßen innovatives und lukratives Tätigkeitsfeld der Informatik. Ob beim hochautomatisierten Fahren, in der Werbewirtschaft, der virtuellen Medizin – oder bei vielen anderen Anwendungen aus dem Bereich Mensch-Technik-Interaktion – werden bereits Programme eingesetzt, die mehr oder weniger gut in Lage sind, das menschliche Gefühlsleben zu analysieren.
Dazu gehören nicht nur die Parameter der emotionalen Befindlichkeit, sondern auch die der Aufmerksamkeit und Anteilnahme. „Wir haben nun untersucht, welche Merkmale und Methoden für den Computer am aufschlussreichsten sind, um herauszufinden, ob Menschen in einer Zuhörersituation aktiv involviert sind oder nicht“, erklärt Dmitrii Fedotov. Der studierte Systemanalytiker promoviert bei Professor Wolfgang Minker am Institut für Communications Engineering der Universität Ulm.
Der 25-jährige ist in Krasnojarsk (Sibirien) geboren und aufgewachsen, und er hat dort an der Reshetnev Siberian State University of Science and Technology studiert. Vor zwei Jahren kam Fedotov dann von dieser hochrenommierten russischen Universität, die zu den fünf strategischen Partnerhochschulen (U5) der Universität Ulm gehört, nach Ulm. Für dieses Forschungsprojekt kooperierte Dmitrii Fedotov eng mit drei Moskauer Wissenschaftlerinnen der Firma Neurodata Lab. Das junge Unternehmen, mit Firmensitzen in Italien, der Schweiz, Russland und der USA – ist spezialisiert auf Fragen der Künstlichen Intelligenzforschung, des Affective Computing und Data Mining. Für das Forschungsprojekt hat das Neurodata Lab einen riesigen Datenkorpus aus Videomaterial auf einer sogenannten EmotionMiner Plattform zusammengestellt. Szene für Szene wurde dafür systematisch „von Hand“ gesichtet und nach bestimmten Kriterien charakterisiert. Welche Emotionen zeigen Sprecher und Zuhörer? Ist der Zuhörer aufmerksam oder unkonzentriert?
Insgesamt wurden dabei mehr als 26 000 Filmfragmente aus 981 Videos verarbeitet. Die kurzen Filmsequenzen, die rund vier Sekunden lang sind, zeigen menschliche Kommunikationssituationen und stammen aus öffentlich zugänglichen Tonfilmaufnahmen von Gesprächen, Interviews, Debatten und Talkshow, die in englischer Sprache geführt wurden. Jede Videosequenz wurde dabei von zehn menschlichen Analysten untersucht. Rund 1500 Menschen waren an der Analyse beteiligt.
Und wozu der ganze Aufwand? „Man braucht diese von Menschen erhobenen Daten als Referenzdaten, um später herauszufinden, wie genau der Computer in der Lage ist, menschliche Gefühle und mentale Zustände zu erfassen“, erklärt Olga Perepelkina.
Die Psychologin ist Chief Research Officer bei Neurodata Lab und war gemeinsam mit Evdokia Kazimirova und Maria Konstantinova an diesem deutsch-russischen Gemeinschaftsprojekt beteiligt. Alle drei Wissenschaftlerinnen promovieren zudem an der Lomonosov Moscow State University (MSU) im Bereich Psychologie. Die eigentliche Herausforderung besteht in der technischen Umsetzung für die automatische Emotions- bzw. Aufmerksamkeitserfassung selbst. Wie bekommt man den Computer dazu, sich anhand des Videomaterials ein Bild davon zu machen, ob ein dort gezeigter Mensch ein aktiver Zuhörer oder eher unbeteiligt ist? Die Wissenschaftler benutzen hierfür das Begriffspaar Engagement - Disengageme
nt, um das Ausmaß der mentalen Involvierung zu erfassen. Für die automatische Aufmerksamkeitserkennung haben sich in den letzten Jahren mehrere Verfahren etabliert, um mimische und gestische Hinweise sowie Körperhaltungen zu erfassen.
Vereinfacht ausgedrückt werden hier Lippen- oder Augenbewegungen untersucht sowie Gesichtsausdrücke oder die emotionale Färbung gesprochener Sprache („Audio“-Faktor). Präziser gesagt geht es hier um den Einsatz von Software-Werkzeugen, die beispielsweise in der Lage sind, in Videosequenzen die Emotionen von Sprecher und Hörer automatisch zu analysieren. Oder es handelt sich um Algorithmen, die in der Lage sind, aus der Bewegung der Lippen die Wahrscheinlichkeit zu berechnen, mit der im nächsten Moment jemand zu sprechen beginnt. Allein für die Gesichtserkennung haben die Forscher ein neuronales Netzwerk mit den Bilddaten von mehr als 10 000 Gesichtern gefüttert. „Wir wollten nun herausfinden, welche Kombination an Modalitäten bei der automatischen Aufmerksamkeitserfassung am effektivsten ist“, so Fedotov. Der Ulmer Wissenschaftler hat dafür alle möglichen Zwei- und Dreifachkombinationen von fünf verschiedenen Erkennungsweisen (Augen, Lippen, Gesicht, Körper und Audio) statistisch kombiniert. Das Ergebnis: Am effektivsten im Verhältnis zum Aufwand erwies sich dabei die Zweierkombination aus „Lippen“ und „Audio“. Gut 70 Prozent aller Fälle lassen sich damit richtig zuordnen; ein Ergebnis, das für die automatisierte Aufmerksamkeitserkennung richtig gut ist. „Beide Merkmale sind direkt mit dem Akt des Sprechens verbunden. Dabei war die Erklärungskraft des „Audio“-Faktors alleine bereits beträchtlich. Für die Praxis heißt dies, dass eine automatische Aufmerksamkeitserkennung, die sich auf die auditiven Merkmale der gesprochenen Sprache konzentriert – Stimmqualität, Tonspektrum, Stimmenergie, Sprachfluss und Tonhöhe – ausreicht, um zuverlässig zu sagen, ob der Zuhörer aufmerksam ist. Wenn der Zuhörer schweigt, helfen andere Merkmale wie Gesichts- und Körperbewegungen dabei, „Engagement“ oder „Disengagement“ zu erkennen. Vorgestellt wurde die Studie im Herbst auf einer großen internationalen Konferenz (ICMI 2018) in Boulder, Colorado.











Highlight

Weitere Topevents

Tödlicher Unfall bei Ehingen - Bus und Auto stoßen zusammen
Ein 58-jähriger Autofahrer starb am Dienstagnachmittag bei Ehingen. Tödlicher Unfall auf der B492Ein...weiterlesen
Kurioses Glanzlicht der Woche: Brand im Ulmer Gefängnis sorgt für große Aufregung - mit hohen Sicherheits-Vorkehrungen
In einer Werkstatt der Justizvollzugsanstalt Ulm ist am Mittwochmittag ein Feuer ausgebrochen. Drei...weiterlesen
Ein Glanzlicht der Woche: Ulms Mega-Kran ist aufgebaut - höher als das Münster - nun kann es für 10.000 Euro Miete pro Stunde losgehen
Die Stadt Ulm erlebt ihre wohl bisher größte Baustelle. Für den Neubau der Wallstraßenbrücke wird nun...weiterlesen
Baustellensprechstunde u.a. am imposanten Kranen am Blaubeurer Ring - und weitere Ulmer Baustellen
Das Update des Baustellen-Managements der Stadt Ulm ist auch für kommende Woche umfangreich -...weiterlesen
Hammer in Ulm: Mario Schneider von der CDU klaut Michael Joukov, Grüne das Direktmandat
Mit Mario Schneider (45) wird wieder ein CDU-Politiker aus dem Wahlkreis Ulm direkt in den Landtag...weiterlesen
Trauriges Glanzlicht der Woche: Drei Männer dringen in Ulmer Wohnung ein und attackieren einen 36-Jährigen
In einer gemeinsame Pressemitteilung der Staatsanwaltschaft Ulm und der Polizei geben biede bekannt: In...weiterlesen
88-Jähriger Fahrfahrer nach Unfall seinen Verletzungen erlegen
Am Montag kam es zu einem schweren Verkehrsunfall bei Erolzheim bei dem ein 88-Jähriger schwere...weiterlesen
Auto nimmt`s mit Straßenbahn auf - 30 Fahrgäste kommen mit dem Schrecken davon
Am Dienstag sind ein Auto mit einer Straßenbahn in Ulm zusammengestoßen. weiterlesen


